
在一项关于人们与建立在机器学习算法上的系统交互研究中,用户的心理模型很弱,很难让UI做他们想做的事情。
我们生活在一个信息泛滥的世界,越来越难去跟踪信息,或者手动为他人策划信息;幸运的是,现代数据科学可以对大量的信息进行分类,并将与我们相关的信息呈现出来。
机器学习算法依靠在数据中观察到的用户知识和模式,对我们可能喜欢或感兴趣的内容做出推断和建议。随着机器学习技术越来越容易被开发人员使用,有一股力量促使公司利用这些算法来改进他们的产品和用户的体验。
人工智能(AI)技术在用户体验方面的典型应用包括:
- 推荐(例如,要看的电影或要购买的产品列表)
- 选择显示什么广告或内容(如新闻标题)
- 交易和特别优惠,个性化,以吸引当前的用户
- 个性化快捷方式,一键访问用户下一步可能要做的任何事情
不幸的是,这些算法通常对最终用户不透明。人们不确定他们的哪些行为会被这些算法考虑进去,它们的输出也不总是那么容易理解。建议和推荐可能是恰逢其时的,也可能是随机的、毫无意义的。通常,这些算法根据不可见的标准对它们的输出进行排序,或者将其分组到不相互排斥的特定类别中。虽然从算法的角度来看,这些决定是有意义的,但对于外行用户来说,它们往往太过模糊,而且与构建内容的传统方式相违背。
在本文中,我们研究了用户在Facebook、Instagram、Google News、Netflix和Uber Driver上与机器学习算法交互时遇到的一些挑战。我们的讨论是基于一项为期一周的日记研究,在该研究中,这些系统的14名现有用户用视频记录了他们与这些用户的互动。
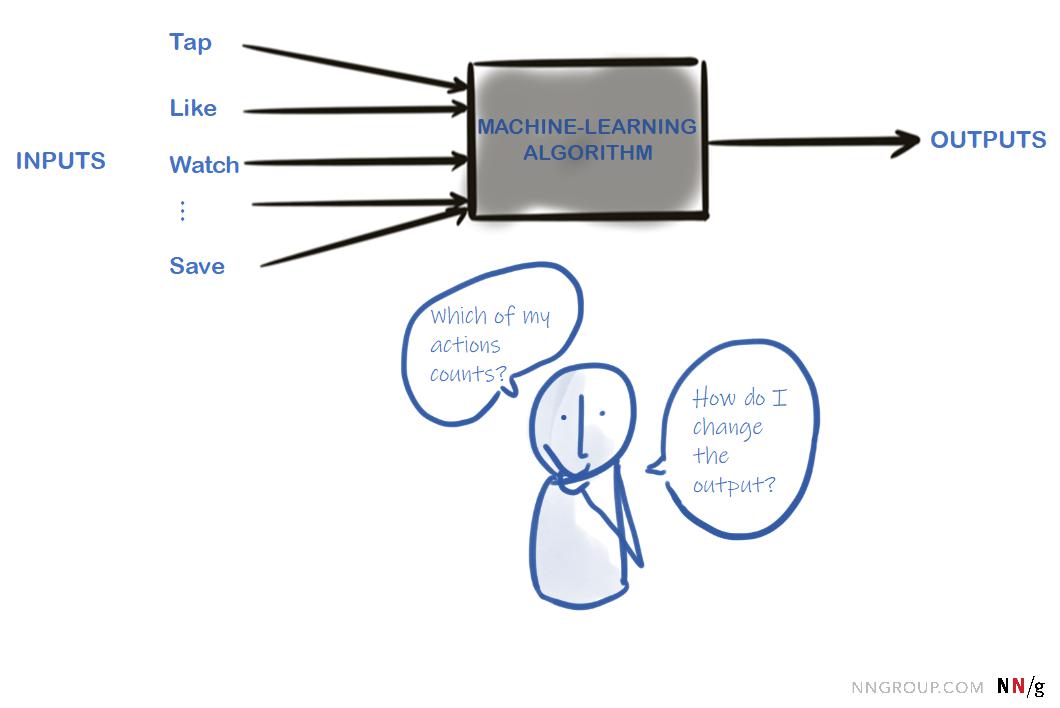
黑箱模型
要成功地与任何系统交互,用户必须创建系统的心理模型。大多数人不是计算机科学家,也不知道软件是如何实现的,但是他们可以根据先前关于软件工件、界面,甚至整个世界的知识,形成像样的心理模型。在许多情况下,他们将系统视为一个黑箱,并决定如何通过处理可能的输入来更改系统的输出。
对于用户来说,机器学习算法就是这样一种黑箱系统。他们知道算法使用他们的一些动作作为输入,并且可以看到输出是什么。要成功地与算法交互,用户必须形成它如何工作的心理模型,并找出如何更改输出以满足他们的需要。创建这个模型有两个大的障碍:
- 不清楚的输入:不清楚哪些用户的行为被考虑进去了,从而产生了输出。
- 对输出缺乏控制:即使人们知道他们的哪些操作被算法视为输入,也不清楚这些输入是否有效地生成了期望的输出。
黑箱模型
我们将分别讨论这些原因。
不清楚的输入
由于输入的不清晰,创建一个准确的黑箱心理模型变得非常困难。有几个原因可能导致输入状态不清晰:
- 这个算法是不透明的——它没有明确地告诉人们哪些行为是重要的。
- 用户并不知道所有可能的输入,例如,因为它们并不局限于系统或平台内的操作,而是来自其他行为数据(例如,访问第三方站点)。
- 输入和输出之间存在延迟:某个操作可能不会立即影响用户在同一会话中看到的输出。
在我们研究的机器学习系统中,Netflix在帮助用户了解他们的哪些行为被推荐系统考虑方面做得最好。Netflix的主页(以及主要类别的登录页面)通常是一长串列表;许多这样的清单都有标签来解释它们是如何被创建的——因为你看了Christine McConnell的《奇怪的创造》,因为你把7月22日添加到了你的清单上,等等。
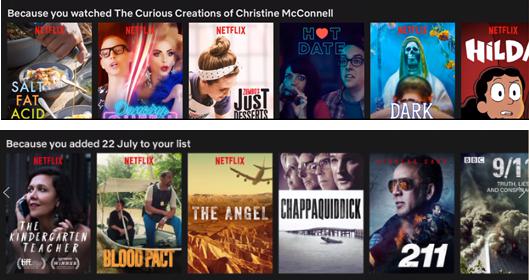
Netflix解释了它的推荐系统使用的一些输入。
人们非常欣赏这些类型的建议,不仅因为他们可以感觉到可以控制,而且因为网站给了他们关于显示内容的有价值信息。
然而,即便是Netflix也未能完全成功地让用户了解其行为是如何被考虑进去以创建推荐的——这也是因为这些行为并没有立即反映在算法的输出中。例如,一名参与者很困惑,她最后一次使用Netflix时看的单口相声似乎并没有影响她的首选。她说:“我的首选改变了——我想这是基于我所看的电影,但这与我所看的电影无关,没有太多喜剧。”
一位Facebook用户花时间在她的新闻推送中隐藏了一个广告,结果却在页面上看到了同样的广告。另一位Facebook用户想知道为什么她的Facebook首选列表和她的Netflix观看列表重叠太多:“首选我不知道他们是怎么得到这些的,我肯定有一些算法或者别的什么,但是我希望它能更好一点,因为很多东西是我几年前看过的,或者是我观看列表上的东西,或者是我完全不感兴趣的东西,所以我想知道他们为什么推荐这些东西。”
Facebook和Instagram用户很难理解他们的哪些行为对新闻推送的内容真正重要。他们认为,算法会考虑他们所关注的新闻摘要中的帖子(通过“喜欢”按钮及其相关内容),从而决定向他们显示什么内容。但是一些关于可能的输入的理论显然是牵强的(有时是技术神话),并且反映了算法缺乏透明性。
例如,一名用户写道:“这既有趣又令人毛骨悚然——昨天我还在说我平时不怎么吃的特爱吃牌越南粉,现在我就看到了这则越南粉墨西哥卷饼的广告;我想知道他们是不是就是把你们的对话录下来了。”一看到夏威夷航空公司的广告,一位参与者半开玩笑半认真地说:“也许他们知道我需要休假。”还有一条:“自从我怀孕以来,我收到了关于怀孕、婴儿用品和人寿保险的广告。”因此,缺乏透明度的输入让用户怀疑——他们认为, 几乎他们的每一个行为(无论是在网上还是在现实世界中)都被算法考虑在内,他们最终相信这些系统比他们在现实世界中更“令人毛骨悚然”、更具侵入性。人们对隐私的日益担忧,以及对谷歌和Facebook等公司掌握的海量数据的认识,助长了这种看法。
谷歌新闻用户普遍对该应用程序为他们所做的成功个性化感到满意,但他们也不确定它基于什么类型的数据。一名与会者表示:“这款谷歌新闻应用似乎迎合了我和我的兴趣……事实上,有三篇与汽车相关的文章,这正是我感兴趣的话题。了解如何生成For you页面是很有趣的。它有我本地的故事,所以它显然知道我的位置,这很方便。”
虽然Uber不提出建议本身, 但据说,它使用机器学习来预测需求,并以价格飙升、促销和游戏化的形式激励司机(例如,Uber司机可以利用“任务”,当他们在指定时间内驾驶一定订单数时,可以获得额外的收益)。Uber算法本身并不基于司机的行为;相反,它的输入可能主要是外部数据,比如历史流量模式。然而,即使是在这种情况下,对输入的清楚了解对司机是否被某些促销活动说服也有一定的影响。例如,一名司机被告知,他需要开车15分钟去接2.3英里以外的乘客,并且有可能有溢价。他说:“这是一个令人恼火的新功能。我认为在过去,你通常只有5分钟的车程(来接乘客),但这次说15分钟的路程和溢价是可能的。我以前有过,但我没做过。我猜这只是一种吸引司机不买票去长途旅行的方式。我不喜欢那种可能的溢价。“司机不明白为什么会有这样的溢价,以及溢价的依据是什么,这让他对Uber的意图产生了怀疑。”
这些事情在近几年也是大家经常讨论的,好像手机的软件都懂得我们的心理一样,无意中说的话可能下一分钟在推荐里就可以看到,下期文章为大家继续介绍黑箱模型的第二个障碍—对输出缺乏控制。
原文链接:https://www.nngroup.com/articles/machine-learning-ux/
翻译:马克笔设计留学




